數(shù)據(jù)處理與存儲支持服務(wù) 圖解技術(shù)原理,讓復(fù)雜變簡單
在當(dāng)今數(shù)據(jù)驅(qū)動的時代,高效、可靠的數(shù)據(jù)處理和存儲支持服務(wù)已成為企業(yè)數(shù)字化轉(zhuǎn)型的基石。這些服務(wù)背后的技術(shù)原理往往因其專業(yè)性而顯得深奧難懂。幸運(yùn)的是,通過直觀的圖解方式,我們可以清晰地揭示其核心機(jī)制,理解其如何為各類應(yīng)用提供強(qiáng)大支撐。這不僅是技術(shù)普及的有效途徑,也讓我們由衷贊嘆現(xiàn)代IT架構(gòu)設(shè)計的精妙。
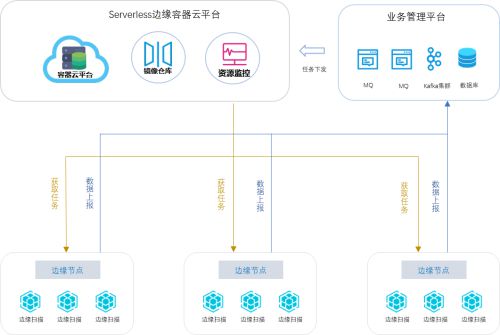
一、 數(shù)據(jù)處理服務(wù)的核心原理圖解
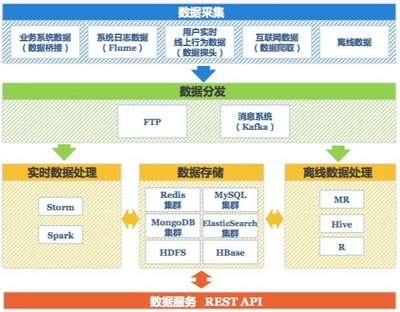
數(shù)據(jù)處理服務(wù)主要負(fù)責(zé)對海量、多源、異構(gòu)的原始數(shù)據(jù)進(jìn)行采集、清洗、轉(zhuǎn)換、分析和計算,最終提取出有價值的信息。其典型技術(shù)棧與流程可通過一個分層管道圖來形象展示:
- 數(shù)據(jù)攝入層:圖示中,各種數(shù)據(jù)源(如數(shù)據(jù)庫日志、IoT設(shè)備傳感器、用戶點(diǎn)擊流、第三方API)像多條溪流,通過Kafka、Flume等“數(shù)據(jù)管道”匯集到中央湖/倉。箭頭清晰表明了數(shù)據(jù)的流向。
- 存儲與批處理層:通常用一座分層的數(shù)據(jù)湖或數(shù)據(jù)倉庫圖標(biāo)表示。原始數(shù)據(jù)作為“湖水”存入(如HDFS、對象存儲),其上方的“數(shù)據(jù)處理工廠”(如Spark、Flink圖標(biāo))對數(shù)據(jù)進(jìn)行批量清洗、轉(zhuǎn)換(ETL),形成結(jié)構(gòu)化的、可用的數(shù)據(jù)層。
- 實(shí)時處理層:一條與批處理并行的“高速數(shù)據(jù)流”管道尤為醒目。數(shù)據(jù)流經(jīng)Flink、Spark Streaming等引擎,進(jìn)行實(shí)時過濾、聚合與計算,結(jié)果直接輸出到儀表盤或告警系統(tǒng),體現(xiàn)了低延遲的特性。
- 分析與服務(wù)層:位于頂端,圖表顯示處理后的數(shù)據(jù)通過API或SQL接口,供給上層的BI工具(如餅圖、曲線圖圖標(biāo))、AI模型(神經(jīng)網(wǎng)絡(luò)圖標(biāo))和業(yè)務(wù)應(yīng)用調(diào)用。
通過這樣的圖解,分布式計算、流批一體、彈性伸縮等抽象概念變得一目了然。
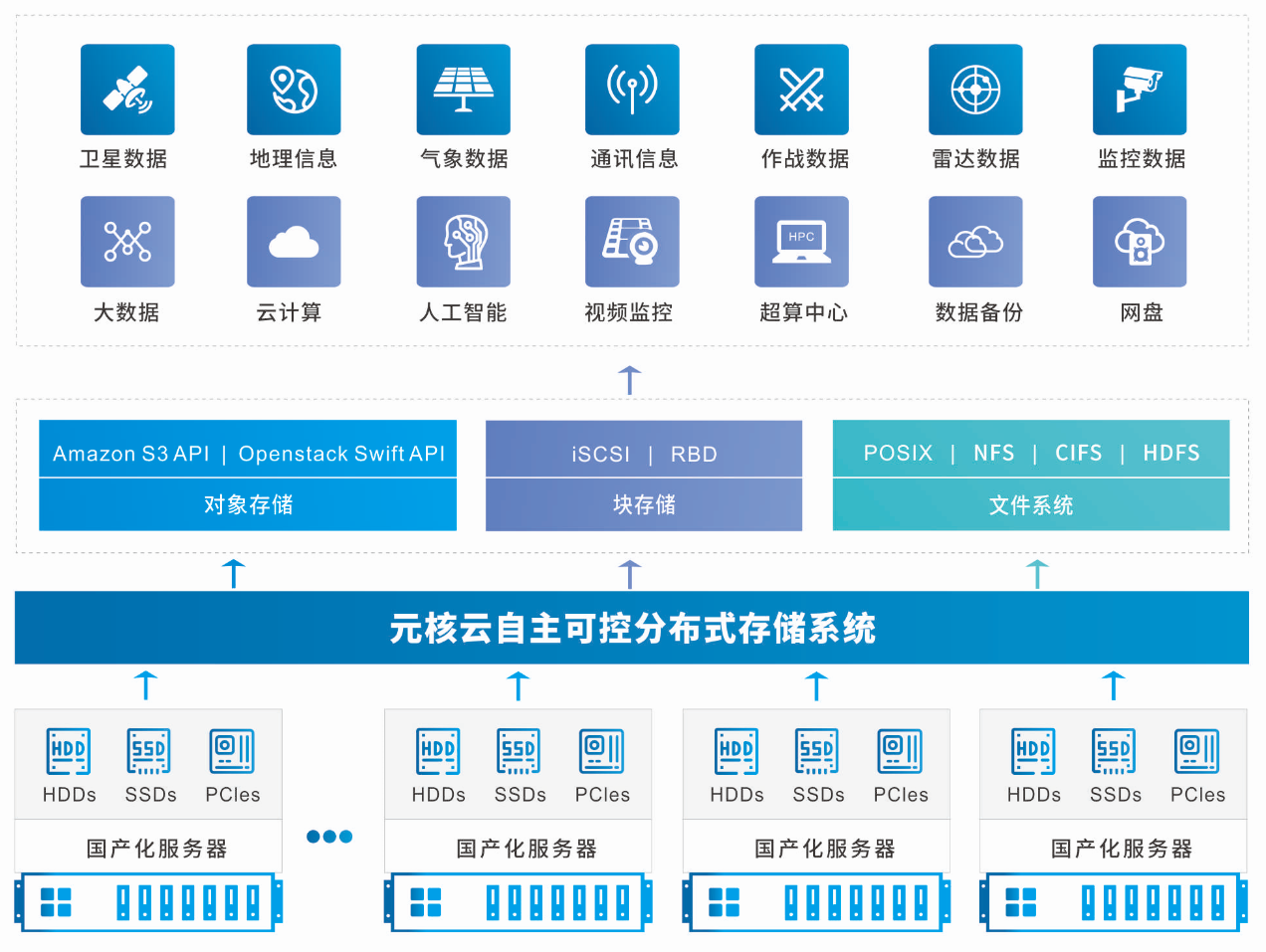
二、 數(shù)據(jù)存儲支持服務(wù)的技術(shù)架構(gòu)圖解
數(shù)據(jù)存儲服務(wù)是數(shù)據(jù)處理得以進(jìn)行的前提,它確保數(shù)據(jù)持久、安全、可高效訪問。其原理可以通過一個“存儲金字塔”或“多模存儲矩陣”圖來闡釋:
- 熱數(shù)據(jù)高速緩存(金字塔頂端):用閃電圖標(biāo)代表Redis、Memcached等內(nèi)存數(shù)據(jù)庫,為高頻訪問數(shù)據(jù)提供亞毫秒級響應(yīng),顯著減輕后端壓力。
- 在線事務(wù)處理(金字塔上層):關(guān)系型數(shù)據(jù)庫(如MySQL、PostgreSQL圖標(biāo),常以表格形式出現(xiàn))位于此層,通過ACID事務(wù)特性保障核心業(yè)務(wù)數(shù)據(jù)的強(qiáng)一致性。圖解中通常會展示主從復(fù)制、分庫分表等擴(kuò)展架構(gòu)。
- 在線分析處理與大數(shù)據(jù)存儲(金字塔中層及基座):
- 數(shù)據(jù)倉庫:如Snowflake、BigQuery的圖標(biāo),專為復(fù)雜分析查詢優(yōu)化,采用列式存儲結(jié)構(gòu)(圖示中數(shù)據(jù)垂直排列),與事務(wù)處理分離。
- 數(shù)據(jù)湖:如一個包容萬象的“湖”的圖標(biāo),內(nèi)部可存放結(jié)構(gòu)化、半結(jié)構(gòu)化、非結(jié)構(gòu)化原始數(shù)據(jù),體現(xiàn)了其“模式在讀時定義”的靈活性。底層常與HDFS、S3等低成本對象存儲關(guān)聯(lián)。
- 歸檔與冷存儲(金字塔底層):用磁帶庫或冰川圖標(biāo)表示,用于存儲極少訪問的歷史數(shù)據(jù),成本極低。箭頭表明數(shù)據(jù)可根據(jù)生命周期策略在不同層級間自動流動。
一張展示“多模數(shù)據(jù)庫”的維恩圖或矩陣圖也很有說服力,它清晰劃分了鍵值、文檔、寬列、圖等不同數(shù)據(jù)模型及其代表產(chǎn)品(如MongoDB、Cassandra、Neo4j),說明了為何要根據(jù)數(shù)據(jù)結(jié)構(gòu)選擇最佳存儲。
三、 協(xié)同工作:支持服務(wù)的完美融合
數(shù)據(jù)處理與存儲服務(wù)并非孤立運(yùn)行。一張典型的“Lambda架構(gòu)”或“Kappa架構(gòu)”全景圖能完美展示其協(xié)同:
- 圖的左側(cè),實(shí)時數(shù)據(jù)流經(jīng)流處理服務(wù),計算結(jié)果存入一個高速的鍵值存儲或OLAP數(shù)據(jù)庫,以供實(shí)時查詢。
- 圖的右側(cè),同一份數(shù)據(jù)也落入數(shù)據(jù)湖/倉,由批處理服務(wù)進(jìn)行更全面、精準(zhǔn)的校正與計算,形成“黃金數(shù)據(jù)集”。
- 通過統(tǒng)一的數(shù)據(jù)服務(wù)層或元數(shù)據(jù)管理(圖中像一個“大腦”或“目錄”),為上層應(yīng)用提供一致的數(shù)據(jù)視圖。
****
圖解的力量在于化繁為簡,將復(fù)雜的技術(shù)原理轉(zhuǎn)化為直觀的視覺邏輯。通過上述圖解,我們不僅看懂了數(shù)據(jù)處理如何像一條精密的流水線將原始數(shù)據(jù)轉(zhuǎn)化為洞見,也理解了數(shù)據(jù)存儲如何像一個智能分層的倉庫系統(tǒng)確保數(shù)據(jù)各得其所、隨時可用。這種清晰的理解,讓我們能夠更好地設(shè)計、選用和運(yùn)維這些服務(wù),從而真正釋放數(shù)據(jù)的巨大潛能。數(shù)據(jù)處理與存儲支持服務(wù),圖解其原理,確實(shí)“真的太贊了”。
如若轉(zhuǎn)載,請注明出處:http://www.ssc931.cn/product/76.html
更新時間:2026-04-28 05:40:45